Consequences of bad health checks in AWS Application Load Balancer
/3.png?width=200&name=3.png)
Ed: I'm getting a bit worried about our VP of Engineering, Aled: he is at his happiest doing cloud war games and pre-/post-mortems! This is the first of many upcoming posts from him about solving customer application challenges on AWS. Notice how, in this post, it's not just a "cloud plumbing" IaaS answer: it's a combination of application (thread pool) AND cloud (AWS ALB) know-how that was the answer. Over to Aled!
I was recently discussing an application outage that an AWS customer experienced several times during spiky, heavy load. This situation can be improved by a minor addition to the web-app and reconfiguration of the load balancer’s health check. I think it’s an interesting case-study for how best to configure AWS Application Load Balancers and auto-scaling groups.
The Architecture
Below is a (simplified) architecture diagram:
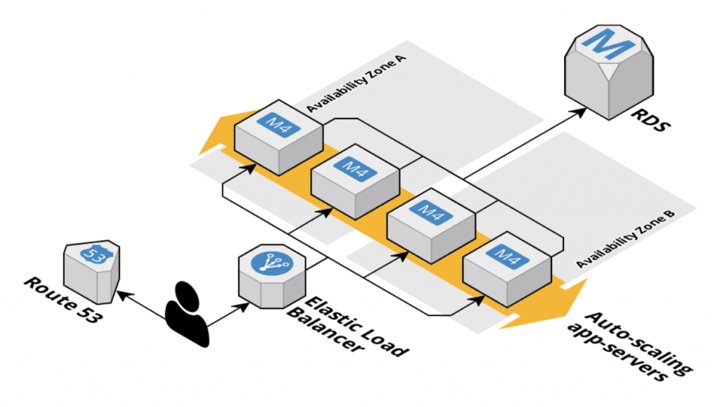
The load balancer and auto-scaling group’s health check used a `/health` HTTP endpoint, which included a check that the database was reachable.
The Problem
Under extremely heavy load, the database was overloaded and became very slow. The load balancer’s health-checks to the app-server timed out, which caused the app-server to be removed from the load balancer’s target group. The auto-scaler would also replace these app-servers due to the failing health-check.
This made the app completely unavailable for a few minutes. The database load would drop to zero, and then this cycle would repeat when the health-checks were passing again.
Unfortunately the alerting was set up to only page people if the site was down for 15 minutes. The cycle repeated in less than 15 minutes, so the alerts were not triggered.
Fix part one: the health-check
The first problem was that the health-check required a response from the database. If the database was responding too slowly, the app-server health check would fail. It blamed the app-server and removed it from the target group.
An improvement would be to use a different endpoint (e.g. `/alive`) that did not check the database connection. This improves things, but not enough.
The app-server handles the HTTP requests in a thread pool pool with a max size. This thread pool was maxed out with customer HTTP requests blocked on database access, with a queue of requests also being managed by the app-server. The `/alive` health-check calls were in this queue so were still slow to respond.
To improve this further, a different thread pool was needed for the health-checks. This is one reason why the application load balancer’s configuration supports a different port for health checks versus customer traffic. A small change to the application code would be to add a listener on a different port, served by a different thread pool with no authentication, so the `/alive` calls respond in a timely manner.
Fix part two: the alerting
The alerts were only raised if the application was down for 15 minutes. This time was presumably chosen because of too many false-negatives in the past or because of an overconfidence in the auto-scaling group’s ability to fix the problem.
I’d recommend that this time be greatly reduced. Instead, rely on a highly available architecture to avoid major outages - if one happens, then respond quickly.
It’s also a good idea to monitor the four golden signals that Google SRE recommend: latency, traffic, errors and saturation. Many outages affect only a subset of requests, meaning your service level objectives (SLOs) are not met but where a high-level health check might still pass. How to do this will be the topic of another blog post.
Fix part three: the database
The RDS MySQL database was the bottleneck in all of this. The long-term solution must address that. A number of options exist for them:
- Monitor RDS through CloudWatch to better understand its performance - for example, have the credits for burst capacity run out, causing IOPS to drop to baseline? Is it CPU or I/O bound?
- Temporarily increase the instance type before the next spike in traffic (only works because they have predictable spikes, and can have short maintenance windows to do the resize).
- Switch to AWS Aurora, to get much better performance at the same price.
- Increase the instance type permanently to better handle the load.
- Create read-replicas, to offload some of the requests.
To improve reliability, they could also check that RDS is configured to run multi-AZ, that the RDS maintenance window is configured sensibly for their use-case, and that CloudWatch alerts are configured to proactively detect performance problems.
Fix part four: postmortems
I was surprised that this problem had affected them multiple times. A healthy way to avoid that is to do a postmortem after each incident. This should be blame-free, it should identify the underlying causes, and should include concrete improvements to prevent this from happening again. It should be shared with the affected customers so they understand you are sorry and will avoid it in the future.
Without such postmortems, history will repeat itself.