The curious case of the spiralling AWS Lambda bill
/3.png?width=200&name=3.png)
Serverless apps and AWS Lambda are normally very cheap. But sometimes costs go wrong. This blog, co-authored with Dan Pudwell, describes one such situation - ever increasing costs, reaching over $900 a month for a Lambda that was scheduled to execute once per hour!
The problem
We began work with a new customer to improve their AWS usage and reduce costs. Analysing their AWS bill, the Lambda costs really stood out - particularly as very little of their application was serverless. Below is the screenshot from Cost Explorer for just the Lambda service.
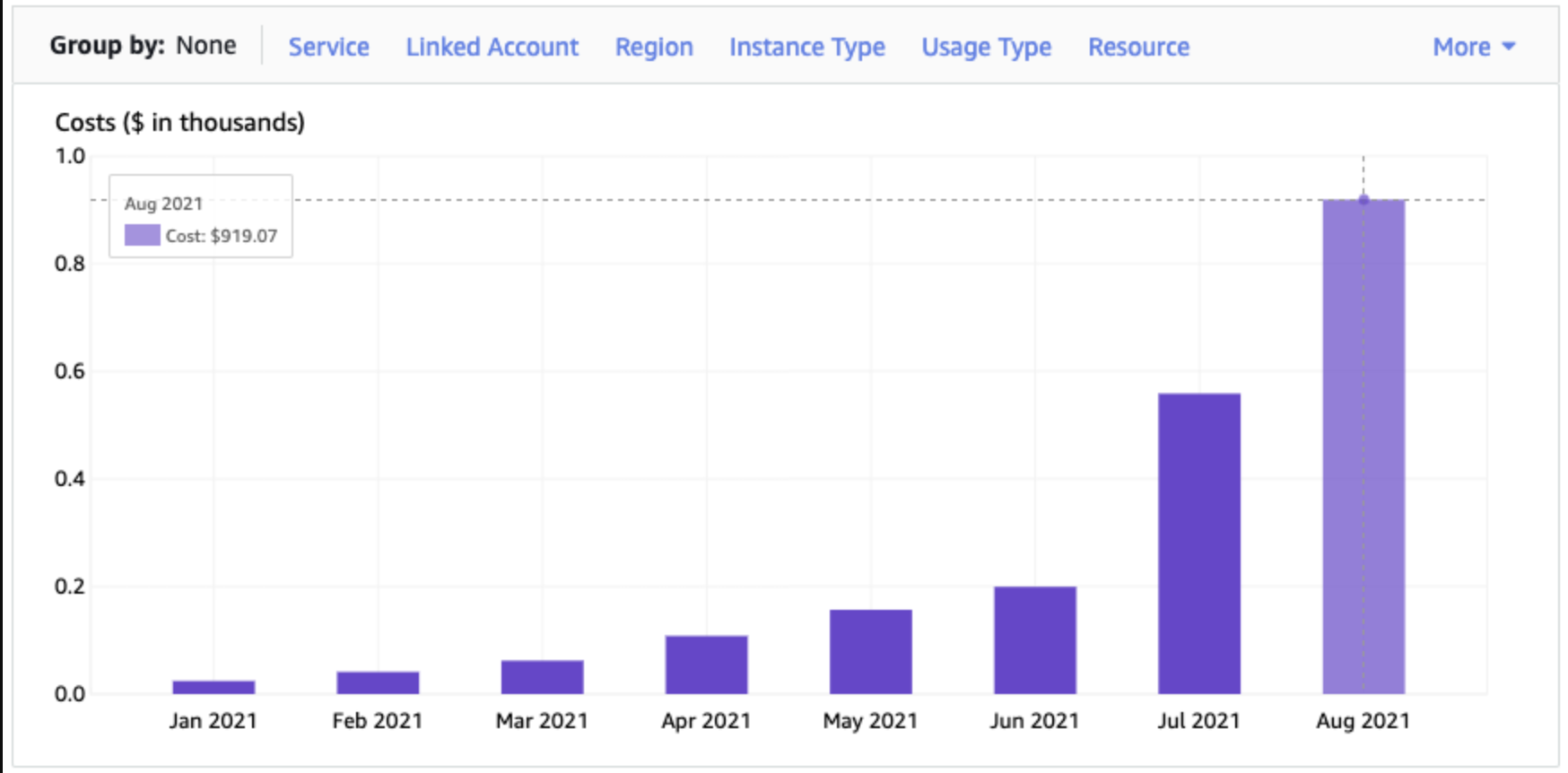
Investigating the Costs
We used Cost Explorer to show the Lambda costs by AWS account - this showed that a dev account was responsible for the vast majority of those Lambda costs. We also viewed costs by region to confirm that these costs were all coming from eu-west-2 (the London region).
Looking in that dev account, we used CloudWatch metrics to dig into what Lambdas were executing. The best metrics to view when investigating these costs were “Invocations” and “Duration” per function (summed over a period of one hour). This showed the costs were almost all caused by one Lambda. Below are the graphs over a 24 hour period.


To summarise the data, this particular Lambda function was being invoked about 15,000 times per hour and was executing in total for an average of 635,000,000ms per hour - i.e. an average of 176 hours of execution every hour!
Well done Lambda for your awesome scaling capabilities. That would have been great if we were doing useful work, but unfortunately this particular Lambda was not.
Now we knew exactly where the costs were coming from, and how it added up to such a big number. Next was to identify why the Lambda was executing so often and for such a long time.
The findings
There was a CloudWatch Event rule setup to invoke this function once per hour. How could it be invoked so many times?!
It turns out the code itself was the culprit. The purpose of the code is to remove empty log streams. When a retention period is set on a Log Group it removes the Log Events but leaves empty Log Streams, hence the need for this Lambda.
It used a fan-out pattern to distribute the work and called itself once per Log Group in the account. The number of log groups had been increasing month-by-month (including every time the CI/CD process executed), leading to 1000s of Lambda invocations.
But why would this add up to 176 hours of execution every hour? Most invocations were reasonably quick - p10 (i.e. the 10th percentile) was 0.9 seconds, p50 was 3.5 seconds. However, some invocations were very slow - p99 was 617 seconds. The reason was rate-limiting: the concurrent Lambda invocations were making too many calls to the CloudWatch API. The Python boto3 library will automatically back-off and retry, but this causes the Lambda to sometimes take a very long time to execute.
The resolutions
As well as fixing this specific scenario, there are more important resolutions to avoid it happening again.
Deleting the empty log groups fixed the issue, and adding a Lambda to automate that deletion means the issue will not happen again. A longer-term improvement is to rewrite the Lambda to not be recursive. Be sure to also configure the CloudWatch Log data retention periods to delete the data from the log streams.
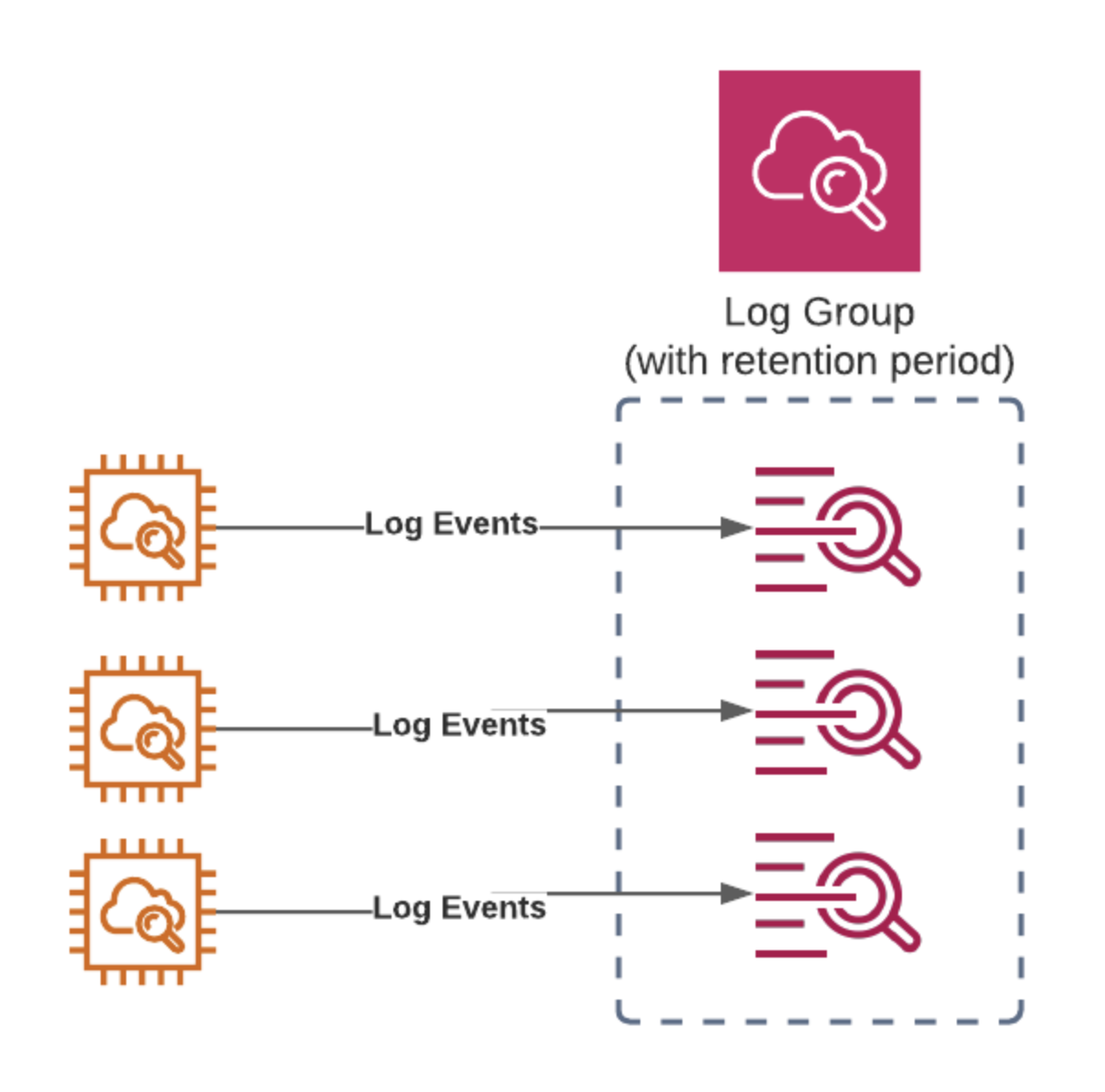
As you can see above a Log Group contains several Log Streams which themselves contain the Log Events. With a retention period set (always a good idea!) this can leave empty log streams which can clutter up our Log Groups. It’s also a good idea to create Log Groups with CloudFormation so they can be cleaned up along with the rest of the stack when not needed anymore.
This customer had no AWS Budgets set up for billing alerts. We set a budget based on expected spend, and alerts at 90%, 100%, 125%, 150%, and 200% for both actual and forecast costs.
We also enabled Cost Anomaly Detection. This helps to reduce any nasty surprises at the end of the month. It may not always help, e.g. if the costs are rising gradually, but it is still a good idea to turn it on.
It is important to set sensible timeouts for Lambda functions. If you expect it to take a certain amount of time, for example 1 second, then you don’t need to give it the maximum 15 minute timeout.
Lastly, all AWS accounts are set up to allow the default 1000 concurrent invocations. We asked AWS Support to decrease this in the dev account. However that is not supported by AWS (please do raise with AWS Support to add your voice to this feature request!).
Conclusion
The irony in this case is that the Lambda was added to cut costs - by deleting empty log streams - but instead cost the customer $1000s of dollars.
Lambda is amazing at scaling, and is priced for what you “use”. This means costs are unpredictable. You want to avoid a price-shock at the end of the month by putting in the right monitoring and alerting.
Also, be careful with your Lambda implementation and testing. What works at small scale may not work as things scale up - handling rate-limiting is a good example of this. Check your downstream dependencies, not everything (even in AWS) can scale as well as Lambda.
Worried about your cloud costs?
Worried you're overspending on cloud? Not sure you’ve got the full picture? Let our experts help get your costs under control. As an AWS Advanced Consulting Partner and FinOps Certified Service Provider we'll improve your cloud cost maturity, fast.
