The Ultimate Guide to AWS T3 Instances Pricing
UPDATE 16/12/2020
A few months after the original blog was published, AWS extended the T3 range with “t3a” instances, which substitute the Intel CPU for an AMD CPU. Although some reports say that the performance is not quite as high, you do get a 10% cheaper instance cost. Given that the oft-cited use case for T3 instances is web serving and other bursty, non-CPU-bound applications, a small drop in CPU power is probably worth the 10% saving.
However if you want the best price-performance and you’re able to handle a CPU architecture change, then the new t4g instances blow all the predecessors away. They’re based on AWS’s own ARM silicon instead of x86-compatible Intel or AMD. If you’re using Java, Python, PHP or any other virtual-machine or interpreted language on Amazon Linux 2, you’ll have very little difficulty switching to t4g, you could see up to a 2x increase in performance, and you’ll save around 20% compared to t3 – not bad!
AWS recently announced a new instance class, T3. These are cost-effective instances which offer great price/performance for workloads that use moderate CPU, with the option to burst to high CPU usage whenever needed. They come in a scale of sizes from t3.nano up to t3.2xlarge. There’s a lot of use cases where switching to a t3 instance type can save you money. But they are not the easiest things to understand, and used wrongly, they can be surprisingly expensive.
Fortunately, with some analysis, it’s easy to come up with some simple rules that will help you make the right decision. I’ve gone through the documentation to find the rules that underlie the T3 instances, and crunched the numbers to come up with some straightforward guidance. In this guide I’ll compare the new T3 instances against each other and the equivalent M5 (current-generation, general purpose) class.
A rapid introduction to T3 instances
1. What are T3 Instances?
T3 instances are aimed at workloads that have variable CPU load, generally low CPU load, but which have the option to consume high CPU levels (“burst”) when required. The T* instance classes generally limit how much CPU bursting an instance can do. T1 instances throttled the CPU if it burst for too long; T2 instances do the same by default but have an “Unlimited” option which bills you for extra CPU credits instead of throttling. With T3, the “Unlimited” option is the default and you must opt out if you prefer you instance to be throttled rather than incurring extra charges.
The way EC2 manages CPU burst is through CPU credits. Your instance will earn CPU credits regularly -- a bit like getting £200 for passing Go on a Monopoly board. Your instance will spend CPU credits whenever it does something with the CPU -- a bit like handing over for money on rent as you go around the Monopoly board. Ideally, when you get around the Monopoly board, you will have spent less than you have earned.
The exact instance type will determine how fast your instance will earn CPU credits. This is defined in CPU credits per hour. For example, a t3.nano instance will earn 6 CPU credits each hour, and a t3.2xlarge will earn 192 CPU credits each hour. You don’t receive your CPU credits in a single “grant”, but instead you receive CPU credits as a constant drip-feed, with millisecond resolution.
2. How do they work?
Your instance has a cap on the amount of CPU credits it can earn and keep in the bank. This cap is set to the amount of credits that your instance could earn in 24 hours. If your bank balance is at the maximum, then it won’t earn any more credits until the balance drops below the maximum again. You will “spend” a CPU credit if you run a CPU core at 100% for a minute. The credits are splittable, and you spend a proportion of a CPU credit for the proportion of the CPU load you are using and the time you are using it for.
For example, if you have a 2-core instance with the first core using 50% for one minute, and the second core using 25% for 20 seconds and then 75% for 40 seconds, then at the end of the minute you will have spent 1.083 credits. These calculations are done with millisecond resolution, just as the earning side of the equation is.
How to predict your charges
This balance between earning credits at a constant rate and consuming credits at a rate proportional to the CPU utilisation is where the cost calculations come in. If you’re spending credits at a slower rate than you’re earning them, then you will not incur any extra charges. But if the opposite is true then you will potentially incur extra charges -- and if you’re not careful, these charges could completely undo the cost effectiveness of your instance type.
The calculations for additional CPU charges involve surplus credits and borrowing against your future earnings potentials, and is a complicated subject best suited for another blog post in the future. However it can all be simplified: - the most important metric you need to monitor is your average CPU utilisation, over all CPU cores, over 24 hours. Using this metric, you can determine how much you will pay -- and, crucially, when your instance type is no longer cost effective for your workload.
If, over the course of 24 hours, your instance is consuming credits at a rate less than or equal to the rate it is earning them, then you will pay only the basic instance price, and no extra CPU charges. The point at which the CPU utilisation perfectly matches the earning rate can be calculated: it is called the baseline and is expressed as a percentage. The baseline varies depending on the instance type as it is calculated from the per-type credit earning rate.
Here is the table of instance types, earning rates and baselines:
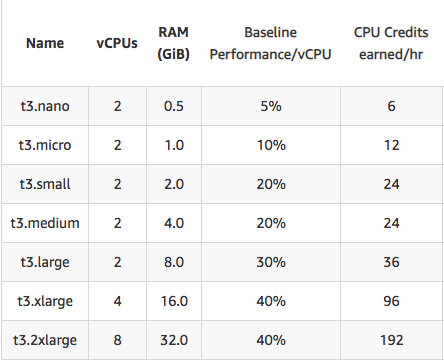 Amazon EC2 T3 Instances Product Details
Amazon EC2 T3 Instances Product DetailsSo if your instance’s average CPU over 24 hours metrics is at or below the baseline, congratulations: you’ve hit the t3 instance sweet spot and are saving money! But if usage is above the baseline, you are being charged for your CPU usage above the baseline. The headline rate is $0.05 per vCPU-hour (equivalent to 60 credits).
The worst case
What would happen if an instance ran with all its CPUs flat-out? What’s the most that would be charged?
This can be calculated fairly simply. A CPU credit is one maxed-out CPU for one minute. Multiply it by the number of CPUs, and then by 60, and you’ll find out how many credits a maxed-out instance will require each hour. Subtract the number of credits that your instance earns each hour. Divide by 60 to convert to vCPU-hours, and multiply by $0.05 to get your excess charge per hour. Add this to your instance’s base price to get the total hourly price.
To use a t3.nano as an example: it has two CPUs, so fully maxed out it will consume 120 CPU credits per hour. It earns 6 credits per hour, so that leaves 114 credits that we need to pay for. That’s 1.9 vCPU-hour, or $0.0950 per hour. In eu-west-1, the instance base price is $0.0057 per hour. Add those two numbers together and we get $0.1007 per hour. This is an eye-watering 18 times higher than the base price!
Here’s the table for all the instance types:
| t3.nano | t3.micro | t3.small | t3.medium | t3.large | t3.xlarge | t3.2xlarge | |
|
Base price per hour in eu-west-1 |
$0.0057 | $0.0114 | $0.0228 | $0.0456 | $0.0912 | $0.1824 | $0.3648 |
|
Maxed-out price per hour in eu-west-1 |
$0.1007 | $0.1014 | $0.1028 | $0.1256 | $0.1612 | $0.3024 | $0.6048 |
| Factor compared to base cost | 18 | 9 | 5 | 3 | 2 | 2 | 2 |
We can see here that the worst case is in the smaller instance types. This is mostly due to the small number of CPU credits earnt per hour.
Right-sizing your T3 instances
So clearly you do not want to use T3 instances for workloads that require lots of CPU power. However there is a good middle ground -- an area where although you are accruing extra CPU charges, you are still paying less than you would if you chose a bigger instance type.
Let’s compare each T3 instance with its next larger neighbour. How much can you go over the baseline before it’s more cost effective to switch to a larger instance type? We can calculate this by working backwards slightly. Starting with the price difference between two instance types, we use this difference to buy vCPU-hours and therefore credits, and add this two the instance’s normal earned CPU credits.
From here we can work out a new baseline. Below this baseline you are saving money over a larger instance type, but above the baseline you would save money if you changed to a bigger instance.
| Instance type | t3.nano | t3.micro | t3.small | t3.medium | t3.large | t3.xlarge | t3.2xlarge |
| Price for next size up | $0.0114 | $0.0228 | $0.0456 | $0.0912 | $0.1824 | $0.3648 | |
| Saving (assuming no vCPU-hour cost) | $0.0057 | $0.0114 | $0.0228 | $0.0456 | $0.0912 | $0.1824 | |
| vCPU-hour that can be bought with saving | 0.114 | 0.228 | 0.456 | 0.912 | 1.824 | 3.648 | |
| CPU credits that can be bought with saving | 6.84 | 13.68 | 27.36 | 54.72 | 109.44 | 218.88 | |
| Effective accrual rate | 12.84 | 25.68 | 51.36 | 78.72 | 145.44 | 314.88 | |
| Effective baseline | 10.70% | 21.40% | 42.80% | 65.60% | 121.20% | 131.20% |
Now this is a useful table. If your t3.nano is regularly using more than 10.7% CPU utilisation averaged over 24 hours, you can save money by moving up to a larger instance type. This pattern is repeated for most of the T3 instance types; if you are using too much CPU, upgrading your instance type will save you money.
Once you get to t3.large this pattern breaks down, but there is still an opportunity to save money. M5 instances have similar CPU and memory configurations, but you are allocated 100% of the CPU power -- there’s no bursting. M5 instances are more expensive than their T3 equivalent, but again there is a baseline where you could save money by switching your T3 class to an M5 class. M5 classes start at m5.large, so let’s compare:
| Equivalent m5 instance type | m5.large | m5.xlarge | m5.2xlarge |
| Price for equivalent m5 in eu-west-1 | $0.1070 | $0.2140 | $0.4280 |
| Saving (assuming no vCPU-hour cost) | $0.0158 | $0.0316 | $0.0632 |
| 14.8% | 14.8% | 14.8% | |
| vCPU-hour that can be bought with saving | 0.316 | 0.632 | 1.264 |
| CPU credits that can be bought with saving | 18.96 | 37.92 | 75.84 |
| Effective accrual rate | 54.96 | 133.92 | 267.84 |
| Effective baseline | 45.8% | 55.8% | 55.8% |
So here we have some more concrete guidelines: if your t3.large instances average over 45.8% CPU utilisations, or your t3.xlarge or t3.2xlarge instances average over 55.8% CPU utilisation (all over 24 hours), then you should switch your T3 to the equivalent M5 to save money.
Conclusion
The new T3 generation of burstable instances will be suitable for many different kinds of workloads. Anything where your CPU usage varies in the short term but is consistent over 24 hours will likely be cheaper when switched to a T3. This includes most server-type activity, where you are consuming CPU when processing requests and idle otherwise, and high CPU usage during your user’s waking hours is offset by low CPU usage during sleeping hours.
Used wrongly T3 instances can cost you dearly, especially at the smaller instance types. However by monitoring the average CPU usage over 24 hours, and referring to the tables in this post to help right-size your instances, you will get the best value-for-money for your instances.
Get a 7-day free trial for our easy-to-use Visual Composer, made to create Cloudformation templates easily and graphically.