Site Reliability Engineering and Platforms: a perfect match for modernising IT operations
/4.png?width=200&name=4.png)
As organisations strive to stay competitive, they are modernising their IT infrastructure and operations. This requires a shift from traditional monolithic applications to more modular and scalable systems.
Site Reliability Engineering (SRE) and Platform teams play a critical role in this process, by ensuring that the underlying infrastructure is reliable and compliant, while also allowing for rapid development and deployment of new features.
In this blog post, we will explore the role of SRE and Platforms in modernising IT, and discuss some of the benefits organisations can reap from these initiatives.
But first, what is Site Reliability Engineering?
Google originated the concept of Site Reliability Engineering (SRE) back in 2003. Simply put, SRE is “software engineering applied to operational problems” (Nikolaus Rauth, Google.)
As DevOps became a mainstay of software development practices, and as tech complexity has spiralled, the need emerged for teams to improve the reliability of services and identify the root cause of outages - and to use automation to reduce the likelihood and impact of future events.

SRE meets this need, with a mandate to ensure services run reliably and resiliently. This contrasts with traditional ops teams, whose responsibility it is to make sure that the infrastructure (servers) are on and reliable. This traditional approach to operations still has a role to play, but SRE, combined with Internal Developer Platforms (IDP), helps to modernise operations to support DevOps at scale and balance the need for developer velocity against the need for stability.
Google’s SRE journey (an abridged version)
Google’s SRE journey (so far) started with a team tightly coupled to their AdWords product. As the product gained more features and different user journeys emerged, this tight vertical product alignment resulted in the team having too many services to manage.
SRE then moved to a more horizontal, microservice alignment but eventually that resulted in too much stratification and meant that developers had multiple SRE teams to deal with for each of the microservices in their product.
This horizontal alignment resulted in service reliability but not overall product reliability, and so it wasn’t totally aligned with Google’s business priorities. The outcome? The SRE function moved back to a vertical alignment but this time was aligned with functions rather than individual products.
SRE Platforms-as-a-Product
The Google SRE team was also able to capitalise on its maturity and extend SRE across the organisation via their SRE Production Platform. This embedded SRE best practices into the developer workflow from the beginning, improving the resilience and reliability of new applications under development.
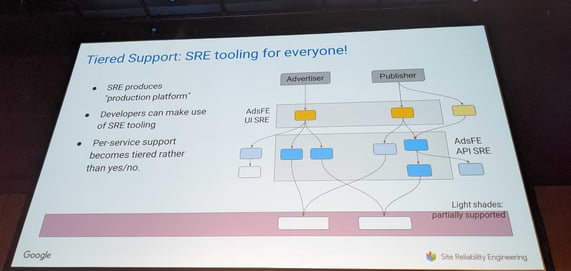
Source: DIGIT Summit, Nov 2022, Nikolaus Rauth Google SRE talk.
Self-service Internal Developer Platforms are a hot topic at the moment, as organisations seek ways to balance velocity and governance, improve resilience and reduce risk.
Read more about Platform Engineering and IDPs here.
SRE is not incident response - it’s part of your golden path to production
When SRE is first implemented, it will naturally have a focus on incident response and resolution. Traditional infrastructure teams are not always equipped to resolve incidents which occur within the digital services and products which run on their infrastructure, and developer teams need to ensure that they’re focused on developing and innovating - not just on keeping their product available. Of course, this doesn’t mean they get a free pass for bad code! SRE should work with developer teams to identify and implement fixes to prevent future issues.
SRE strives to reduce developer distractions, but does not replace the development teams’ responsibility for bad code in production.
Google’s journey shows that SRE teams are essential for resilience, not just reliability. It is automation-powered resilience that drives high customer satisfaction, especially as complexity increases.
However, Google’s journey also demonstrates the value of having a product-mindset, and packaging up SRE services for self-service Internal Developer Platforms.
This is a shift away from the “you build it, you run it” mentality that accompanied DevOps adoption, and recognises that as the number of services grows it is not possible for developers to both build and run their products.
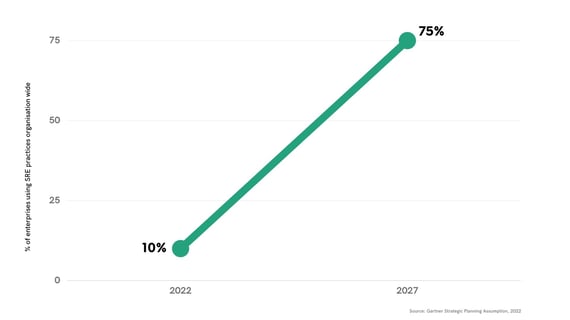
By 2027, 75% of enterprises will use SRE practices organization wide to optimize product design, cost and operations to meet customer expectations, up from 10% in 2022
- Gartner, Strategic Planning Assumption
So, SRE should form part of your response to this tech complexity, not just the incidents that arise from it. And why is addressing this complexity important? Because complex systems are vulnerable, and vulnerable systems break, resulting in poorer customer satisfaction.
SRE helps to bridge the gap between DevOps and traditional I&O and feeds into the tools and blueprints available via your Internal Developer Platforms to embed SRE best practices into products from the outset. It is part of your golden path to production, and to improving customer satisfaction.
What does a good SRE function look like?
Your SRE function is a product of skills, tools, and culture. SRE “is not just a rebranding of an existing operations team. It requires a collaborative engineering mindset and a demonstrated ability to continually learn, improve and share knowledge”.
Skills
SRE teams need to be able to combine software engineering mindsets with systems thinking.
They should be skilled in:
- Automation
- Root cause analysis in complex environments
- Performance engineering
In addition to technical skills, SRE functions must also be able to demonstrate:
- Open and collaborative mindset
- Flexibility and agility
- Learning and communication
Tools
Good SRE requires:
- automation
- monitoring/alerting
- incident response and
- configuration management tools.
Great SRE teams use automation to bring these point-solution tools together into one monitoring and control plane, and to automatically alert to issues and resolve them before they become a problem.
They should also be able to package their tools and services up for wider consumption via Internal Developer Platforms.
At Google, they found that as the number of services managed by the SRE team grew, and the success of the SRE team became widely recognised, they could package up their expertise into an SRE Production Platform which was shared with the wider Google development team. This provided a self-service way for teams to benefit from SRE tools, automation and best practices without adding load to the core SRE team.
Culture
Technical challenges are just the tip of the iceberg when it comes to implementing SRE. Often, cultural factors related to collaboration, customer-centricity and DevOps mindsets prove to be more of a barrier to SRE success.
For SRE to thrive, cultural evolution is necessary - especially focusing on the customer, collaboration and trust…I&O leaders must incubate and grow their SRE efforts over time, taking care to enable learning and change
- Gartner
The goal of an SRE team is to enable developers to run their services reliably from the outset, and to reduce the likelihood of an issue reoccurring in the future. This means that SRE teams should foster a mindset of:
- identify the problem
- automate the solution
- eliminate the problem
- update your IDP for continuous improvement
Leaders should also foster a culture of openness and blamelessness, rather than one of finger-pointing and fear. The SRE team works with developer teams to address the root cause and introduce processes and fixes to ensure the issue does not happen again; this kind of collaboration is better fostered in a blame-free environment.
Conclusions
Site Reliability Engineering is part of your DevOps and Internal Developer Platform maturity. It updates IT Operations for the complex, hybrid environments in which Ops teams and Developer teams have been trying to run resilient services. Combined with Platform Engineering, SRE is a powerful tool for enabling good governance, self-service and resilience whilst supporting developer velocity.
Sources: Gartner, Quick Answer: What Is Site Reliability Engineering?, By Analyst(s): Daniel Betts, George Spafford, Hassan Ennaciri, Chris Saunderson, June 2022